A Deep Dive into PostGIS Nearest Neighbor Search
Table of Contents
In this post, we’re going to take a deeper dive into the Postgres and PostGIS internals to find out how this actually works. By the time we surface you will have a better understanding of the advanced technical capabilities and unparalleled extensibility of Postgres. You’ll also appreciate how the open philosophy of Postgres has fostered a development community whose collaboration over many years has provided powerful features that benefit numerous users.
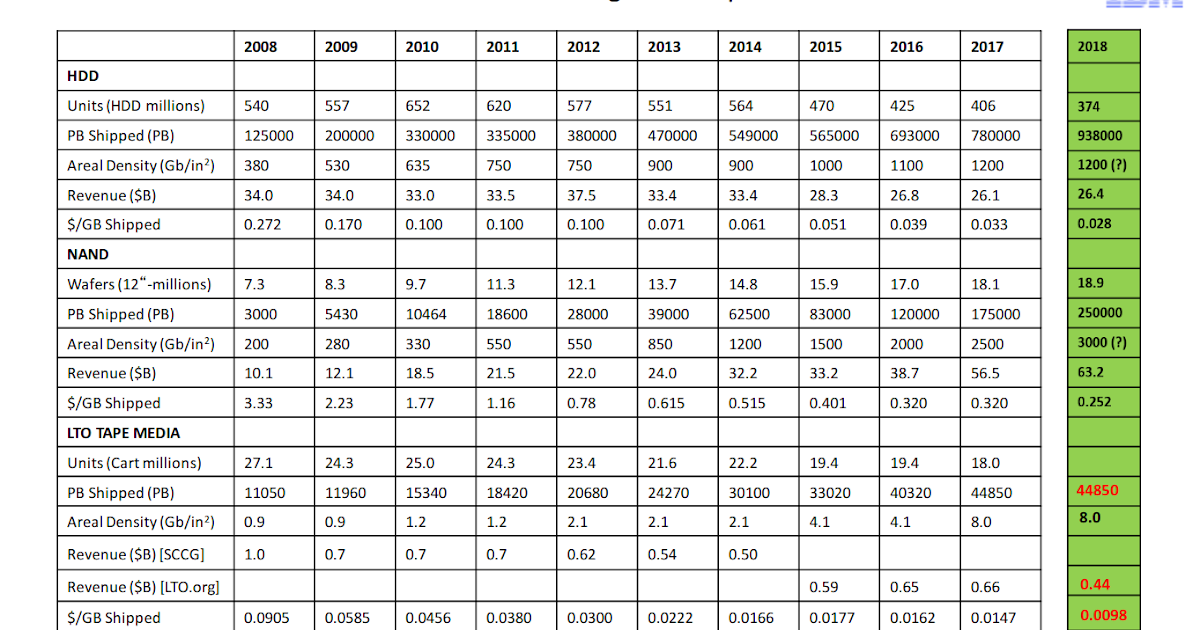
As a recap, the problem is to find the nearest feature, or the K-nearest features, to a given target feature out a set of spatial features. The obvious way to do this is to compute the distance from each candidate feature to the target feature, and choose the K-smallest distances. It should also be obvious that this will be extremely slow if the number of candidates is large (it is common to run queries against datasets containing millions of features).
Source: crunchydata.com